
🧠 Is Beating AI Giants Possible? 4 months Later, How Is Deepseek Doing?
Deep dive into the efficiency of AI models and their costs for the environment, the hidden secrets behind the success story and my tips as a tech investor...

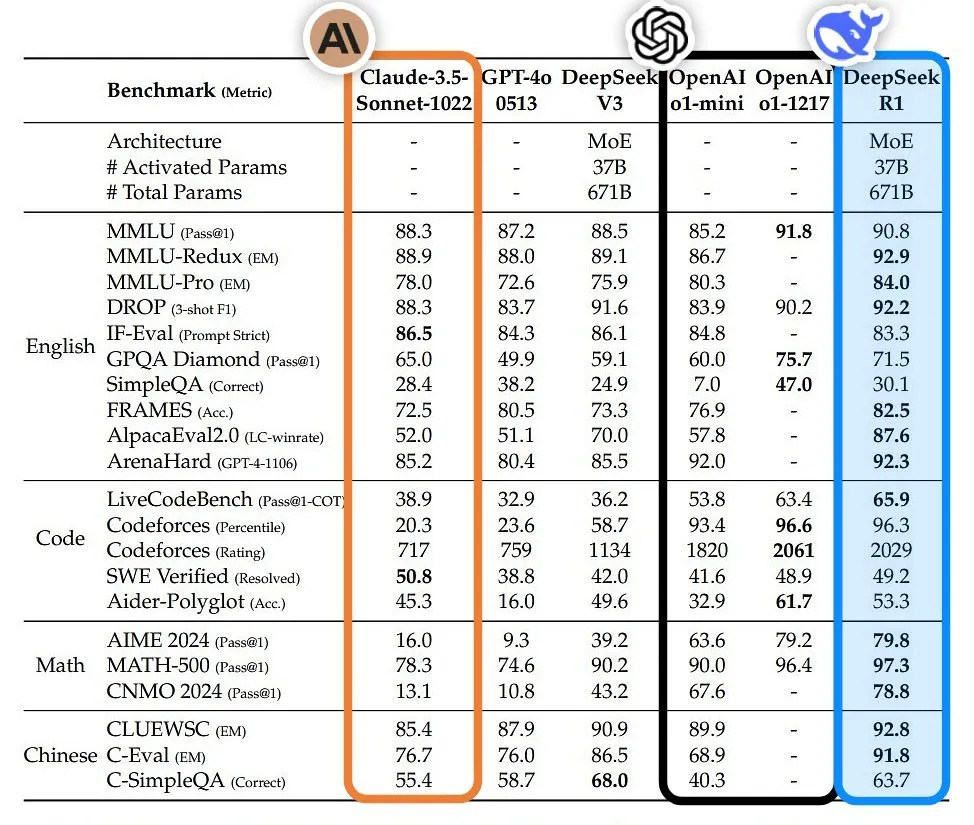
On January 20th, something remarkable happened — and almost no one saw it coming. DeepSeek, a relatively unknown AI startup from China, released the first open-source reasoning model that matched OpenAI’s o1 performance.
Not just comparable. Not a close second. Matched it.
What made it even more jaw-dropping? They pulled this off with 1/10th the training cost and with inference costs that are 20–50x cheaper than any frontier lab.
This wasn’t a Silicon Valley-backed moonshot. DeepSeek had no famous founders, no flashy investors, and no billion-dollar war chest. Just 100 people. Zero VC. A dream. And 10,000 GPUs powered by pure will.
To understand how they pulled this off, I went deep into the origin story — and found a tale of collapse, constraint, reinvention, and one of the most impressive pivots in AI history.
Preface: 1/10th of the energy = 1/10th of pollution?
So, if Deepseek is indeed as efficient with 1/10th of ressources needed, let’s build an approximate, illustrative comparison based on publicly estimated compute usage, energy intensity, and car-equivalent emissions. This won’t be exact but will help us grasp the climate footprint of OpenAI vs DeepSeek at full deployment scale.
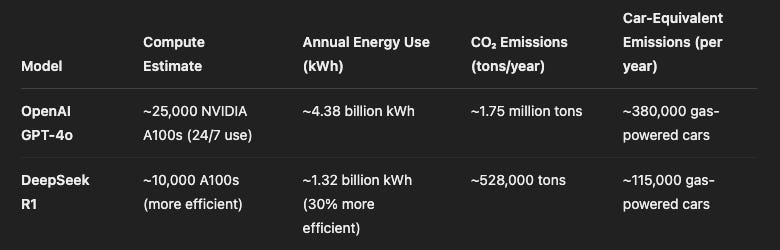
🔍 Takeaway:
OpenAI’s GPT-4o running at full scale emits as much CO₂ annually as ~380,000 cars
DeepSeek R1, while powerful, is leaner — emitting the equivalent of ~115,000 cars, thanks to more efficient architecture and inference costs.
In climate terms, efficiency isn’t just a cost advantage — it’s a carbon advantage.
That’s why we’re watching teams like DeepSeek so closely.
Anyway, let’s dive into DeepSeek 🌀
⚙️ 1. Origins in Obscurity
Let’s rewind. Back in 2007, three engineering students — Xu Jin, Zheng Dawei, and Liang Wenfeng — met at Zhejiang University, one of China's top science and tech institutions. They bonded over a shared obsession with algorithms and the idea that software could one day out-trade humans. Their goal?
Build a fully AI-driven quant fund from scratch.
But from the beginning, they made a decision that would set them apart: they refused to play by traditional hiring rules. Instead of bringing in industry veterans, they focused on identifying raw, untapped talent — students and early-career engineers who were brilliant, intensely curious, and unafraid to break things.

Liang later explained:
“Our core technical roles are filled by people who are just starting out — fresh graduates or maybe a year or two into their careers. We bet on fire and flexibility over polish and pedigree.”
📈 2. The Rise of High-Flyer
After years of low-key experimentation and algorithm development, the trio formally launched High-Flyer Quant in 2015. Armed with unconventional hiring principles and deep conviction in machine learning, they scaled rapidly — but quietly.
By 2021, they had become a powerhouse in the world of Chinese finance:
Over 10,000 NVIDIA A100s deployed across their custom-built AI research and trading stack
A seat among the top 4 quant funds in China, with a staggering $15B in assets under management
And, perhaps most impressively, $140 million invested directly into their internal AI infrastructure
Here’s the key detail: none of that $140 million came from venture capital.
Every dollar was reinvested from their own trading profits. High-Flyer was a cash machine during its prime — generating consistent alpha through proprietary quant strategies. Rather than distribute all those earnings, they doubled down on internal innovation. They believed AI was not just a tool, but the future of trading itself. So they built what was effectively a private AI lab inside a hedge fund.
This wasn’t about external funding or VC rounds. It was organic growth reinvested at massive scale — a rare move in either finance or tech.
But like many rocket ships, their trajectory outpaced their controls.
📉 3. The Crash of 2022
2022 brought the reckoning. The markets turned volatile, models began underperforming, and cracks emerged in High-Flyer’s system. The speed that once made them dominant now became their Achilles’ heel.
One of their flagship funds saw a 13.1% drop in a single quarter — a brutal hit in quant finance.
Another fund ended the year with an 8.1% net loss, erasing years of gains.
The CEO, Liang, issued public apology letters to investors and partners — a rare move in a deeply private industry.
New investments were frozen, internal morale was shaken, and the firm entered survival mode.
What had once been a shining example of AI-driven trading now looked like it had scaled too quickly, with too little redundancy, and too much reliance on a narrow band of strategies.
But the real trouble was still ahead.
🧨 4. Existential Risk
In 2023, the Chinese government shifted its regulatory focus. Amid an economic slowdown, a collapsing real estate market, and increased social pressure, the government cracked down hard on the quant industry.
High-frequency traders were scapegoated for destabilizing the stock market. The CSI300 Index, China’s blue-chip benchmark, was in freefall — and officials wanted someone to blame.
The policy response was swift and aggressive:
One quant competitor was banned from trading for three days as punishment.
Another firm was barred from opening index futures for a full year.
Strategy disclosure rules were enforced — meaning firms had to submit algorithms for review before execution.
The government even floated the idea of 10x transaction fee increases — effectively threatening to make quant trading unviable.
High-Flyer was directly in the line of fire.
Their fund performance stagnated, and since 2022, they’ve underperformed the market by over 4%. What had once been a technological edge now risked becoming a liability in the eyes of regulators.
For most firms, this would have meant the end. But for Liang and his team, it became a moment of radical reinvention.
🔁 5. Reinvention Through AI
Rather than fold under pressure, High-Flyer made a bold move.
In early 2023, they spun out DeepSeek, a standalone AI research lab built from the ashes of their quant ambitions.
They took the very assets that had powered their trading empire — 10,000 GPUs and a culture of raw, curious talent — and redirected it toward one goal:
Frontier artificial intelligence.
No external capital. No partnerships. Just internal conviction.
And they stuck to their philosophy: no fancy resumes, no big-name academics, just hungry minds and hard problems.
Liang:
“We don’t believe in AI wizards. Our team is made up of fourth-year PhD students, recent grads from top schools, and young engineers who just want to build something great.”
This wasn’t a pivot. It was a rebirth.
🚀 6. Breakthroughs Begin
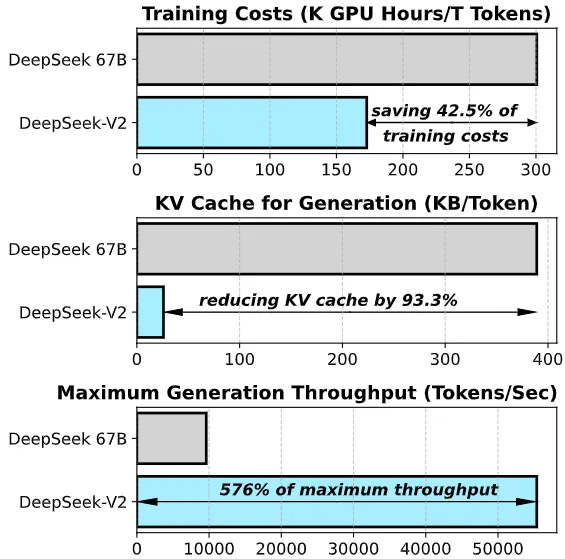
By early 2024, DeepSeek started turning heads. Their release of DeepSeek v2 included a series of technical breakthroughs that caught even seasoned AI researchers off guard.
They introduced:
Multi-Latent Attention combined with Sparse Mixture-of-Experts (MoE) architectures, reducing training costs by 42.5%
A novel approach to KV caching, slashing memory usage by 93.3%
A 5.76x boost in generation throughput, unlocking faster and more scalable inference
They weren’t just building models — they were rewriting how large-scale reasoning could be done more efficiently.
Then in September 2024, they dropped a bombshell:
R1-lite-preview, their first reasoning model built with a novel test-time reinforcement learning strategy. It became the first serious competitor to OpenAI’s o1 — and they beat every other lab (open or closed source) to the punch.
🎁 7. The Christmas Bombshell
On Christmas Day, when most labs were quiet, DeepSeek dropped v3. And it changed everything.
Trained for just $6 million, DeepSeek v3 was now playing in the same arena as ChatGPT-4o and Claude 3.5 Sonnet. But with major architectural upgrades:
Multi-Token Prediction, enabling longer and more coherent generations
FP8 Mixed Precision Training, improving speed without sacrificing accuracy
Distilled Reasoning from R1, allowing inference to retain logic without extra compute
An Auxiliary-Loss-Free Load Balancing Strategy that made multi-GPU setups cheaper and more stable
Then came the pricing reveal:
DeepSeek API: $0.14 per 1M input tokens, $0.28 per 1M output
OpenAI: $2.50 in, $10 out
Anthropic: $3 in, $15 out
That’s not just disruption — that’s economic warfare in compute.
🔓 8. Then Came January
January 2025 marked the moment they made it real.
DeepSeek released the first open-source reasoning model that matched OpenAI’s o1 — not with imitation, but through a pure RL pipeline, no supervised fine-tuning, no reward models.
They published their techniques, invited others to build on their work, and dropped a bombshell into the AI open-source movement.
No tricks. No API lock-in. Just real tools for real builders.
Their pricing still made jaws drop:
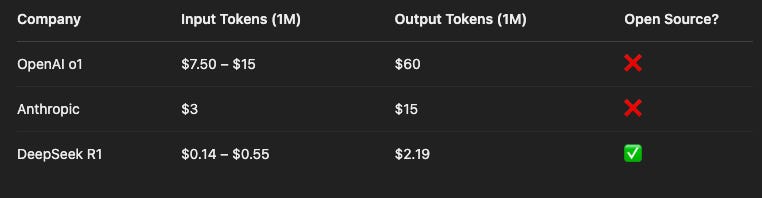
For Open AI: The pricing isn't just high — it's gatekeeping innovation.
Most startups and academic labs can't afford to prototype at these levels. Meanwhile, DeepSeek just made the floor drop out.
For Deepseek: The delta isn’t small — it’s an entirely different cost model. This opens the door to startups, universities, and creators who could never afford to play at the frontier before.
🧭 So What’s the Lesson?
DeepSeek is more than a company. It’s a case study in adaptive strategy.
They proved you don’t need:
❌ A billion dollars
❌ A famous founding team
❌ Dozens of ex-Google PhDs
You need:
✅ A willingness to rebuild
✅ The discipline to invest in your own capabilities
✅ The belief that constraint breeds creativity
In the age of adaptation, those who survive aren’t the biggest or the loudest.
They’re the ones who know how to bend without breaking — and use every crisis as a catalyst.
DeepSeek just gave us a masterclass.
💼 My Take as an Investor:
So, about investing in AI today… I’ve been watching the AI capital stack shift in real time — and here’s my truth:
It’s never been more expensive to get in.
And there are no ways to get in now (unless scammy stuff).
Back in 2018, you could invest in an LLM (OpenAI, Anthropic, Cohere, etc.) for under $100M pre-money. That door? Long gone.
In 2023, you might have had a shot at riding Mistral’s early rounds or Anthropic’s Series B. Today? Good luck.
The late-stage hype wave has made these deals functionally uninvestable for all but the megafunds and only at sh** valuations.
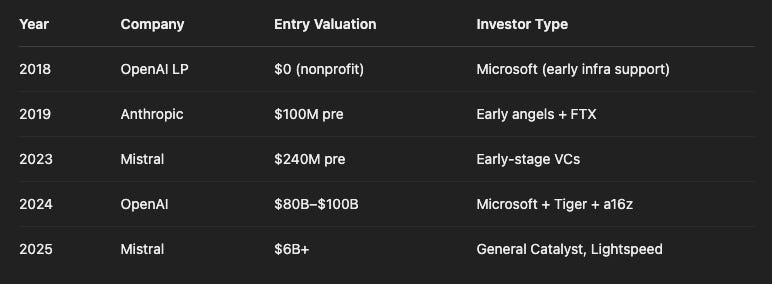
Getting in now means paying 100x the entry price with less upside.
And if you think these are safe bets, just remember: the market can rotate away from LLMs in a heartbeat.
🧭 So What’s the Play?
Here’s my take after watching the capital flows, founder pivots, and infrastructure scramble across the AI economy:
Investing directly in LLMs is too late — unless you're already writing $100M+ checks into late-stage megadeals with limited upside and massive dilution. The returns have been frontloaded. The risk-reward ratio? Not attractive anymore.
Data centers look OK for now, but it’s a long game — more like 15 years than five. There’s no guarantee the demand curve for training/inference sustains at today’s hype levels in the short term. Long-term? Maybe. But you’ll need deep pockets and patience to play that infrastructure game.
Capital is concentrating into the usual suspects — OpenAI, Anthropic, xAI, Mistral. If you're not already inside that circle, you’re either overpaying to enter or getting no allocation at all. And most of these aren’t really “startups” anymore — they’re compute states with corporate APIs.
AI Agents is the new SaasS — Definetly going to make lots of ARR money there but hard to justify anything for an exit above 1 billion dollar really as you are dependant of the APIs of LLMs and that will increase (a lot) overtime.
So what’s left for potential billion dollars exits?
My conclusion: the real opportunity is AI + Hardware.
We’re entering the era where software intelligence starts acting on the physical world.
That means:
Voice-native operating systems
Robots that move, assist, and learn in real time
Humanoids powered by foundational models like GPT-4o and Claude Sonnet
AI copilots for warehouses, homes, farms, factories — not browsers
This is where the next 100x will come from. 3 Examples:
Things like this Build Robotics, augmenting traditional trucks to build solar farms autonomously.
Or hyper specialized things like this SafeAI, powering autonomous construction and mining robots.
We’re talking about applied intelligence with a body — where the marginal cost of labor, logistics, and decision-making drops across entire sectors. The winners won’t just be labs with the best model — they’ll be the ones who ship physical products, not just API endpoints.
So here’s how I’m thinking about it:
✅ Bet on open-source challengers like DeepSeek to lower costs and democratize reasoning
✅ Bet on AI-native hardware companies — from voice devices to full-stack robotics platforms
✅ Bet on the picks-and-shovels: energy, cooling, edge compute, chips built for real-world latency
✅ And above all, bet on useful AI. Things that solve actual problems in messy, physical environments.
The AI hype is maturing towards the end of the cycle.
Now comes the deployment phase — and that’s where builders who know to combine atoms and bits will dominate.
The next trillion-dollar category isn’t just AI.
It’s AI and hardware in motion.
– Djoann Fal
The Adaptive Economy